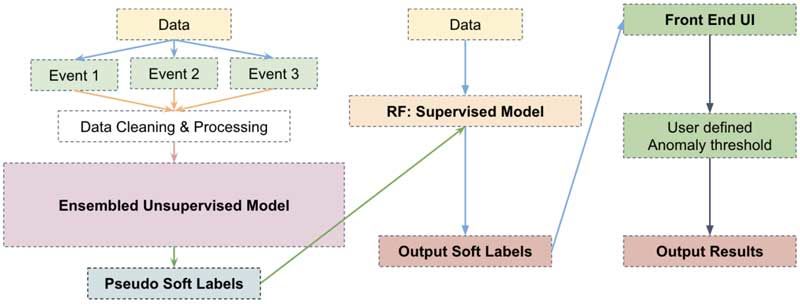
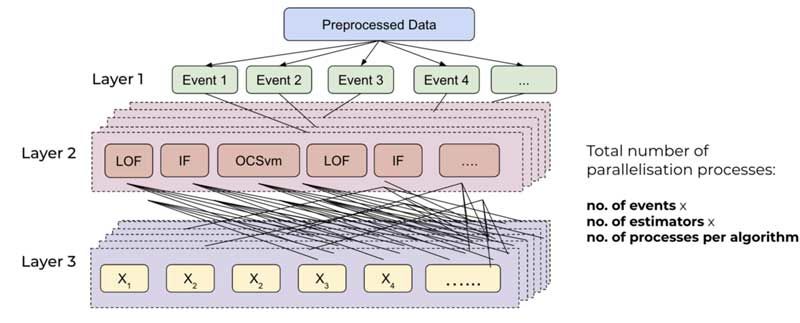
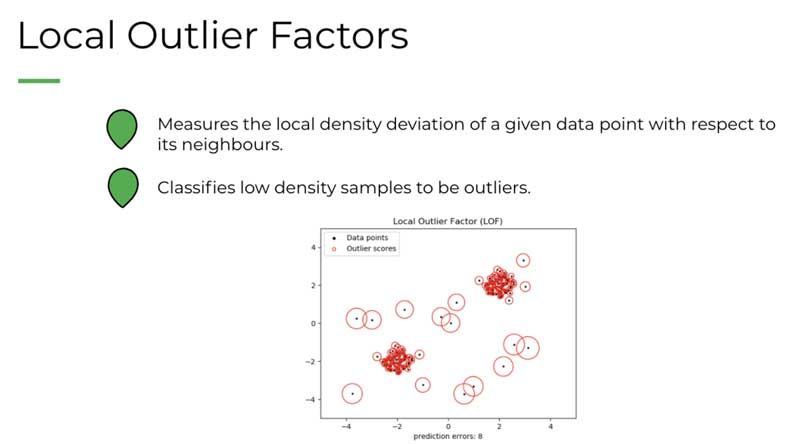
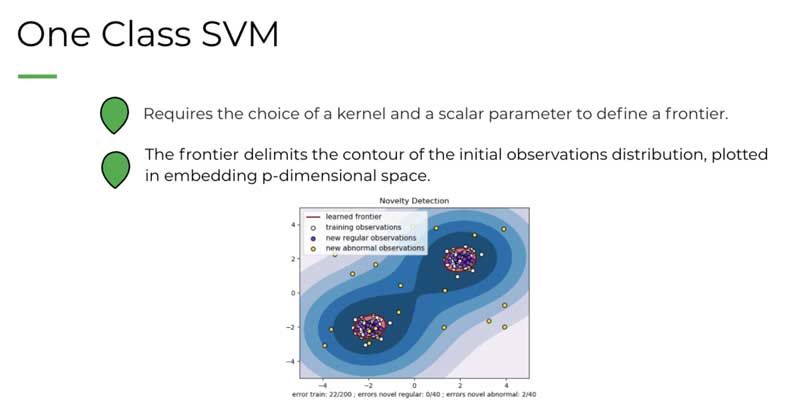
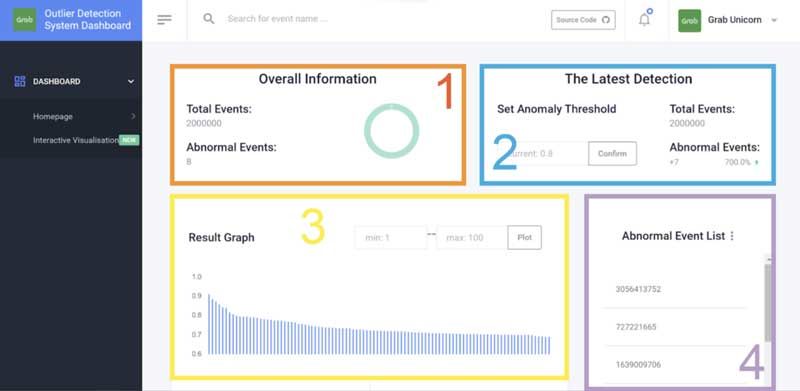
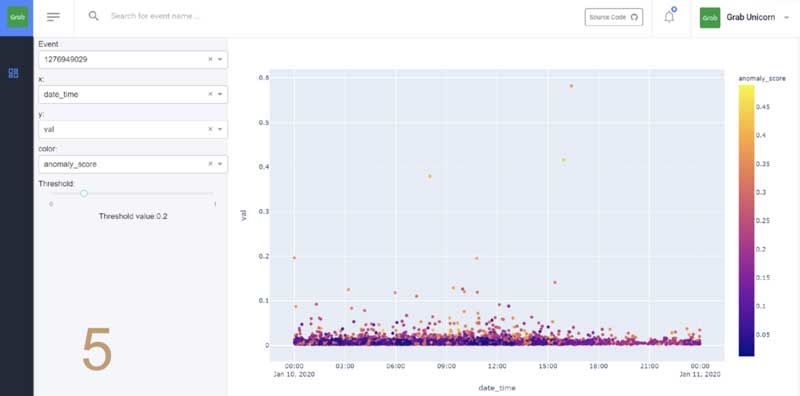
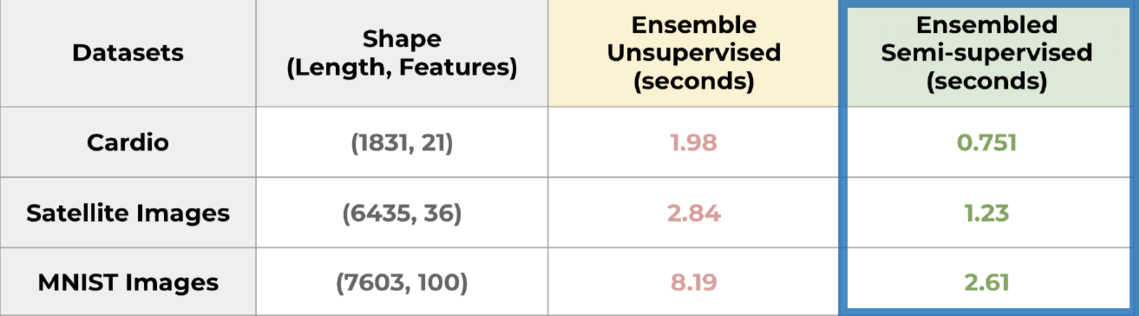
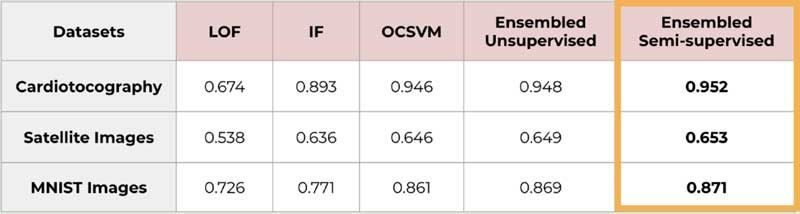
CAPSTONE DESIGN SHOWCASE 2020
GOING VIRTUAL
-
DAYS
-
HOURS
-
MINUTES
-
SECONDS
COMING SOON




Team members
Gary Ong Guan Jie (ISTD), Wang Zijia (ISTD), Chan Chen Chang Joseph (ISTD), Li Yahan (ESD), Lin Hao (ESD), Lin Xiaohao (ESD)
Instructors:
Cyrille Pierre Joseph Jegourel, Stefano Galelli, Ying Xu
Writing Instructors:
 Gary Ong Guan Jie
Information Systems Technology and Design
Gary Ong Guan Jie
Information Systems Technology and Design
 Wang Zijia
Information Systems Technology and Design
Wang Zijia
Information Systems Technology and Design
 Chan Chen Chang Joseph
Information Systems Technology and Design
Chan Chen Chang Joseph
Information Systems Technology and Design
 Li Yahan
Engineering Systems and Design
Li Yahan
Engineering Systems and Design
 Lin Hao
Engineering Systems and Design
Lin Hao
Engineering Systems and Design
 Lin Xiaohao
Engineering Systems and Design
Lin Xiaohao
Engineering Systems and Design
Gary Ong Guan Jie
Information Systems Technology and Design
Wang Zijia
Information Systems Technology and Design
Chan Chen Chang Joseph
Information Systems Technology and Design
Li Yahan
Engineering Systems and Design
Lin Hao
Engineering Systems and Design
Lin Xiaohao
Engineering Systems and Design